I read Data-Oriented Design by Richard Fabian but will mostly cover the methodology (DoD) not the book. Let’s get it out of the way and I’ll try not to belabour it:
- I didn’t enjoy this book and wouldn’t recommend it.
- The author seems to have a chip on his shoulder about object-orientation and he spends too long saying it’s bad. He should have spent more time on DoD instead, that’s what I wanted to learn.
- I had to read some sections several times trying to understand his use of negatives and double negatives. It could have been written in a more straight forward way.
- The sample code are both not to my taste and inconsistent, mixing different styles even within one example.
- Surely there must be something better than this.
It’s about all the data
Data-oriented design concentrates on the underlying data in any given system. Data tends to be stored in a very simple way as integers, floats and strings within arrays. It does allow for common structures for the domain such as a 3D vector, meshes or images. The book spends a chapter on relational databases and normalising your data into standard forms. You probably won’t be using a database but the data is laid out in a similar way. There are a couple of reasons for doing this.
I can get behind the first reason. By paying attention to how your data is laid out in memory you cluster data that is used together in an operation. This means that when the CPU fetches new data into the cache that most or all of that data will be relevant. Every single byte in the cache line will needed by the operation and is used by the operation. No extra time will be spent waiting for memory reads until another entire cache line is needed. Without this attention data is often laid out so that all the data for one owner is together. Operations tend to need some but not all of the data for one owner. Most of each cache line is taken up by data irrelevant to this particular operation. The process will often have to wait for new cache lines to be read. By putting extra effort into data layout you get higher performance.
I wasn’t convinced by the second reason. He feels that this alternative layout is better for extensibility, debugging and probably other things as well. It is true that new features would tend to introduce new arrays rather than modify existing ones. He acknowledge any difficulty from keeping track of all these separate arrays or synchronising data between them.
Example particle system
I made a few very simple particle systems to look at some performance numbers. The test creates a number of particles and randomly assigns a velocity to 10% of them. The particles are them simulated for a number of frames. The faster the simulation can be finished the better. There are two object-oriented designs and two data-oriented designs:
- Object-oriented design:
- Simulate moving particles – Moving particles are updated every frame, static particles are skipped.
- Simulate every particle – Every particle is updated every frame, static particles not skipped they just have zero velocity.
Data-oriented design:
- Indexed velocity – Every particle has a position but only moving particles have a velocity. Moving particles are updated every frame.
- Velocity – Every particle has a position but only moving particles have a velocity. Moving particles are updated every frame. Static particles are kept in their own array out of the way.
// Object-oriented design
struct Particle {
Vector3 position;
Vector3 velocity;
// Extra data to represent particle name, colour, lifetime, etc.
...
};
std::vector<Particle> particles;// Data-oriented design, indexed velocity
struct IndexedVelocity {
size_t index;
Vector3 value;
};
std::vector<Vector3> positions;
std::vector<IndexedVelocity> velocities;// Data-oriented design, velocity std::vector<Vector3> movingPositions; std::vector<Vector3> velocities; std::vector<Vector3> staticPositions;
You can take a look at the full source and the performance but here is the graph:
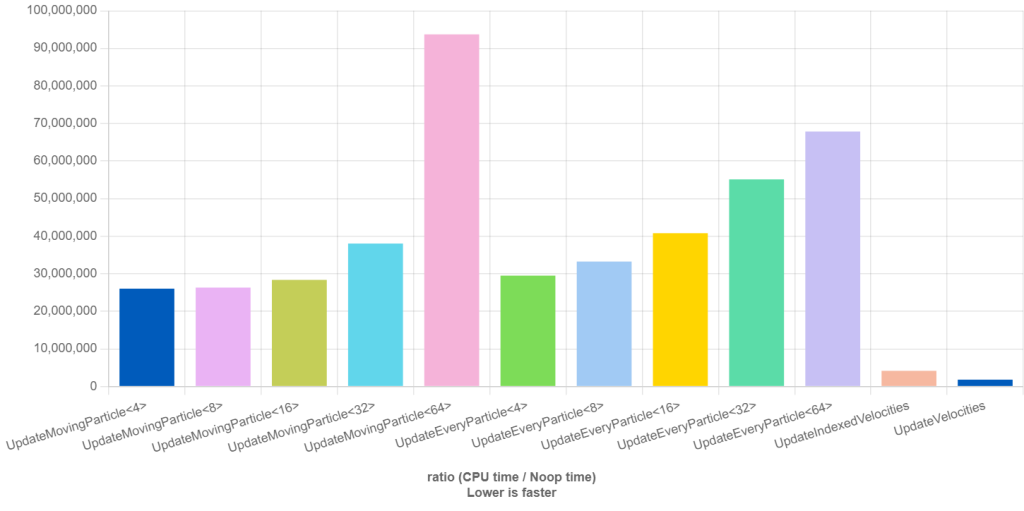
Both object-oriented designs show similar performance,
there isn’t really a performance gain from trying to skip the vector addition.
The first set of bars UpdateMovingParticle<4> to UpdateMovingParticle<64> show that the more
junk data in the struct the slower the simulation.
The second set of bars UpdateEveryParticle<4> to UpdateEveryParticle<64> shows the same.
Both data-oriented designs show much better performance.
The UpdateIndexedVelocities is 6 times faster than the fastest UpdateMovingParticle.
The UpdateVelocities is 14 times faster than the fastest UpdateMovingParticle.
Having all the data in one place really does make a difference.
However details matter, if 50% of the particles are moving we get this:
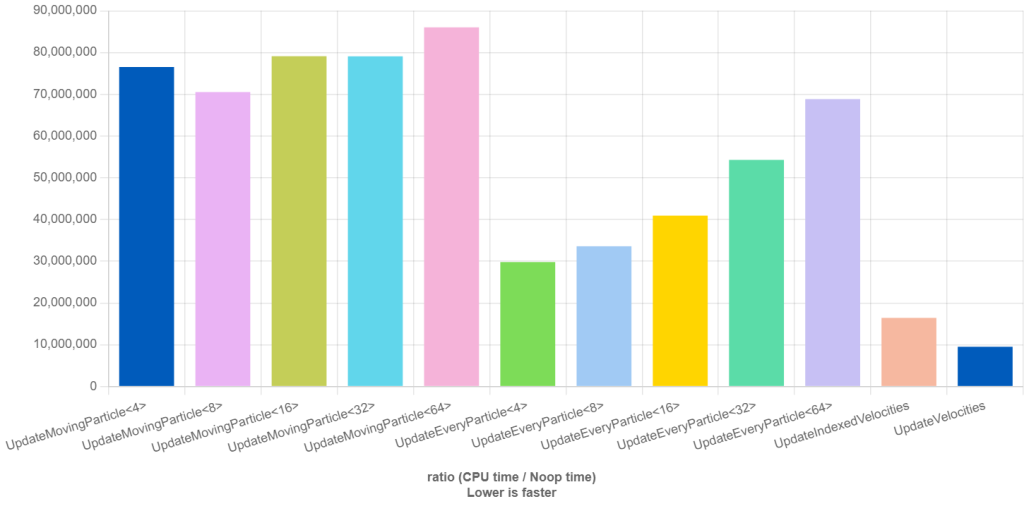
The UpdateMovingParticle approach is almost uniformly slow.
It tries to skip unnecessary additions but that seems to be messing with
branch prediction.
The other approaches are slower because more work has to be done but have the same speed relative to one another.
How to layout
In object-oriented design a collection of data tends to be an array of structs (AoS). As we’ve seen this tends to leave gaps between the data for a given operation. In data-oriented design a collection of data tends to be a struct of arrays (SoA). This means that relevant data is all tightly packed together.
It’s not just about switching from AoS to SoA. In existential processing you avoid performing checks because you already know the answer for this data. You can avoid storing and checking boolean or enum states by storing items in an array specific to that state.
The book uses an example of enemies in a video game with regenerating health. It’s tempting to have an array of floats to represent the health for each enemy. Running through all enemies to see if they needed to regenerate would be wasteful. A first step at optimisation would involve using separate arrays for injured and healthy enemies. Running through the injured enemies reduces the amount of processing. A second step at optimisation might discard the array for healthy enemies entirely. If you know they are healthy then presumably they have the default health value for that enemy type. This reduces the overall memory overhead and setup processing.
Later on the book covers hierarchical level of detail and a similar tick that can be used. Lets say a wave of enemies is made up of squads and a squad is made up of soldiers. If a wave is far away from the player it is not necessary to simulate soldiers or even squads. Instead the wave can be abstracted, perhaps as a central position and radius. As the wave and player get closer first squads and then individual soldiers can be spawned. As the wave and player get further away soldiers and squads are de-spawned. If the player fights an injures a solider then it would be nice to show this even if the solider is re-spawned. The essentials of the solider can be stored in a memento that is attached to it’s squad. When the solider is re-spawned the memento provides the information to turn it from a generic solider to a more specific one.
So pack the data you are going to use at one time as tightly as possible. If you can get away with have little or no data by using context then do so.
A halfway house
In-between object-oriented design and data-oriented design is component-oriented design. This uses smaller structs or components and combines them together to make the functionality for each entity. This can be organised in two ways:
- Each entity is explicit, an object and contains a collection of components.
This is how the Unity game engine works. - Each entity is implicit, there is nothing but components some of which relate to the same entity.
Managers can then be used to update all the components related to one operation, say, rendering or physics at one go. You get some of the performance benefit of DoD but with fewer structural changes.
Optimisation
The book has a few good ideas here, often with a game focus.
Take a planned approach to optimisation. Give each system a time budget and make sure they stick within that budget. Rendering, physics and similar systems can be given a certain number of milliseconds per frame. If you add up all the budgets you know the milliseconds per frame and therefore the frame-rate.
Removing an item from an vector is normally an O(n) operation. However that’s only if you need the vector to stay in the same order. If you don’t care about the order then it’s O(1). Something like:
template <class Iterator>
void unstable_erase(std::vector<Type>& values, Iterator it) {
auto last = std::prev(values.end());
if (it != last) {
std::swap(*it, *last);
}
values.erase(last);
}Object-oriented vs data-oriented design
The author of the book had the general option that data-oriented design was better. In the introduction he allows that an object-oriented project can be setup faster and that there is a more obvious mapping between the real world problem and the code. Presumably he judges that extra setup time and a harder job translating problem into code is worth it. He says a lot of other negative things about object-oriented design but it’s so extreme I have to question it.
I have been persuaded that in performance critical systems a data-oriented design has a big advantage. However to get that performance benefit I think my time and thought has to be spent developing the code. I worry about other consequences. This database like approach is very open. All the data is exposed to everyone and anyone can change it. If they follow all the rules for manipulating the data then it’s fine. However as we all make mistakes I don’t generally trust everyone, even myself, to follow the rules. The limited interfaces and private variables of object-oriented design protect the developer from themselves and everyone else.
On balance
I think it’s a situation of advantages and disadvantages on both sides. If final performance is most important and development effort is less important then use data-oriented design. If final performance is less important and development effort is more important than use object-oriented design. Maybe use some of one and some of the other depending on the system.
Leave a Reply