
Program Design
The LIS has been designed as two components: the Internal Model and the External Model.
The Internal Model handles the actual creation, manipulation and destruction of cells. Also the Internal Model manages the actual structure of the spreadsheet data and maps this to the External data model. The External Model handles the user interface, passes cell contents to the Internal Model, displays cell contents and provides actions such as paste, fill down etc.
This design has several advantages. The coupling between the Internal Model and the External Model is kept to a minimum. It would therefore be a simple matter to replace either model. There is a high level of cohesion as each model has a well defined and separate purpose.
The Internal Model
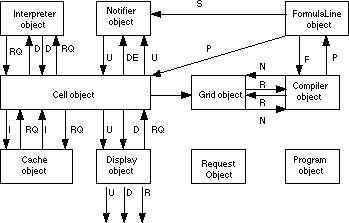
| P : Program | F : Formula | N : name |
| R : reference | S : start | U : update |
| DE: dependency | I : image | RQ : request |
| D : data |
The simplest way to explain how the Internal Model functions is to work through the sequence of events caused by a cell being given new contents.
The External Model passes the cell name and the formula, as strings, to the Formula Line object. The Formula Line object passes the formula to the Compiler object which creates a Program from the formula. The Compiler uses the Grid object to replace all cell name references with their valid Cell object references. If a cell name is out of bounds or incorrect then it does not exist and therefore an error is reported. The Compiler passes the Program, containing the compiled formula, back to the Formula Line. The Formula Line object then passes the Program to the Cell object and signals to the Notifier object to start.
The Cell Object knows that it has a new Program and that it must have its data value updated. The Cell object also knows all other Cell objects that depend on it. So the Cell object sends an update signal and a list of all dependent Cell objects, whose values are now invalid, to the Notifier. The notifier in turn takes note of all cell dependencies, and their dependencies and so on; the notifier has built an exhaustive dependency list. By this method the Notifier is able to detect any cyclic dependencies. If any Cell object appears twice as the Notifier is parsing dependencies then there must be a cycle and an error is reported.
The Cell now tells the Interpreter object that it wants its Program to be evaluated. The Interpreter attempts to evaluate the Program, if any Cell object references appear in the program then the interpreter must request these Cell data values. If a requested Cell data value is unavailable then that Cell's data values must be calculated.
A Cell object must store it's value. If the value is a string or a number then it may be stored inside the Cell object, otherwise it is an image and must be stored in the Image Cache. When a Cell has it's image value requested, it must in turn request the image from the Image Cache. If the Image Cache does not hold that image then the Cache requests the image from the cell which causes the cell to request the image from the interpreter.
The Cell now contains a new value and so it sends the updated value to the External model via the Display object.
Another example of the Internal Model process is when the External Model requests an image update. This case is similar to that above, in that the cell will get a request and then go through the same process of requesting its image value from the cache.
We shall now discuss the internal modules, explaining our ideas for their implementation and the actual degree to which these ideas were implemented in our SLI.
The Spreadsheet Object
The spreadsheet object is the only item which the interface need couple with. It allows formula to be added and retrieved from the Internal Model. Data values can be requested and will be returned at some point, perhaps after some idle time has been given. There are also calls for the copying, pasting and moving of cells. The spreadsheet object was important in allowing connections to be made between the various component objects of the Internal Model.
The implementation of the spreadsheet object has three parts: the construction and destruction of the spreadsheet requires large numbers of objects to be created or destroyed, the passing on of messages from the interface to the appropriate internal object, and returning connections to the internal objects.
The Program Object
The program object's main purpose in the internal design is to store an abstract syntax tree representation of the spreadsheet commands. It is created by the compiler, and is used by the cells to pass their programs to the interpreter, which extracts the AST from the program object and evaluates the expression contained within.
The advantage of using an object like this is that we obtain a useful encapsulation of a program and the operations on it that can safely be passed around by other components of the spreadsheet without them knowing anything of its internal design. This allows the program object to be changed in the future without affecting components of the spreadsheet that do not use it directly.
The Grid Object
The grid performs several services all relating to the mapping of a cell name, such as "B3", to a cell reference which leads to the working information of the cell and also mapping in the other direction. During our investigations of HCI issues it was decided to give each cell two names, one beginning with a letter and the other beginning with a number, the grid supports both. Insertion and deletion of rows and columns is handled by the grid to minimise change and recalculation needed. Similarly it handles copying, pasting, and moving of cells. Because spreadsheets may be very large the grid also provides a system to minimise memory usage. The grid can remove those cells which contain no important information and recreate them on demand.
The implementation of the grid provides the name translation and memory compaction systems. Insertion, deletion, copying, pasting and moving are not available. A redesign of the grid would separate out the last three features to another object. The grid would be simplified and it would be easier to add new concepts such as "fill down" to the spreadsheet model.
The Compiler Object
The compiler is a simple recursive descent parser. A formula string is given to the compiler which then translates that string into an abstract syntax tree. All cell name references are converted to cell object pointers during compilation. See the External Specification for the formula language grammar. The abstract syntax tree is then packaged into a program object which is passed out of the compiler .
The compiler also decompiles program objects and returns the abstract syntax tree as a string. This in effect translates a program object into the string formula from which it was formed.
There are several features that we had planned to include in the compiler but did not have time to fully implement. The infrastructure to handle compile errors has been provided but the compiler has not implemented these. At the moment there is no type checking for the arguments to an image processing function. Both of these would be simple to implement but we do not have enough time to do so.
The Formula Line Object
The formula in object has two tasks, to add and retrieve formula. When retrieving a formula it must locate the cell to which the cell name refers, extract the program and have this decompiled into a formula. When adding a formula it must again locate the cell, have this compiled, insert the program and then signal the notifier to propagate any changes.
The implementation of the formula line relies on the grid and compiler to catch any errors so that it can abort the process.
The Notifier Object
The notifier object should be alerted whenever a cell has its program changed. The notifier records the cell references until it receives a start signal and then goes through all the cells, and the those they depend on to try and find a cycle of dependency. All those cells in cycles must be given a error value. Those not in cycles should be told to update their values.
The implementation of the notifier detects cycles by starting with each cell that has been changed and performing a search through the graph of its dependents. If the cell from which the search started is found then a cycle is present. This is not an efficient algorithm but was done for ease of implementation. To notify cells of changes another search is done from the starting cells. A closed list of cells was used in each case to prevent work from being done twice. The cycle notification system does not work properly, it will notify all cells that have changed, not just those it the cycle.
The Request Object
The request object is used to hold the information needed to get a value from a cell back to the interface, perhaps requiring it to be recalculated. There are several items stored within: the width and height of any images need, the priority of the request, the number of cells that the value will depend on, the program of the cell, the origin and destination of the request. New requests can be made from old one so that they can be passed among the several objects involved in value retrieval.
The implementation of the request object also provided an < operator to allow the interpreter to easily determine which request has the highest priority.
The priority of the object in our implementation is determined by the priority value. When two requests have the same priority value they go on to examine the number of cells that program will depend on. Those which depend on more cells should come first.
The Display Object
The display object has two jobs, notifying the interface that a cell has changed and getting the new value of the cell to the interface. A cell notifies the display if a change occurs. The cell reference given has to be converted to a cell name, which the interface can understand, and a callback made to inform the interface. When a data value is required the display makes a request object which contains all the information needed to retrieve the value and send it back to the interface. The appropriate cell is located using the grid and the request sent. Later when a reply arrives the value is sent to the interface via a callback routine.
Later it was found to be useful if the display could store auxiliary information to be used in callback routines. Similarly it would have been helpful to store auxiliary information with each data request but there was insufficient time to implement this.
The priority of an request is not set because the External Model does not currently use the priority system.
The Cell Object
The cell object stores the program which can be evaluated to obtain a value and acts as a communication hub between the side of the Internal Model dealing with getting programs and the side dealing with evaluating programs. To allow updates to be propagated quickly between cells each cell stores references to cells that depend on it. To manage this data each cell must examine new programs when they are received and send messages to those cells referenced by it.
The implementation of the cell requires many additional pieces of information to be stored because of its connections to the notifier, grid, display, cache, and interpreter. It is highly dependent on all these objects to do its work. There are situations in which more work is required of it. When a cell is removed from the spreadsheet, using delete row for instance, this may result in programs in other cells becoming bad and these cells will need to mark the programs with this detail.
The Image Cache Object
The image cache is a store for images which are used in the spreadsheet. An image can then be retrieved from the cache faster than it could be recalculated. For non-images, cells cache their own value but for two reasons this is not done for images. Firstly each cell may have multiple images associated with it, each of a different size. It simplifies the mechanisms of the cell if finding the correct picture is handled elsewhere. Secondly images take up much more space than other data values, so it may not be possible to hold all the images which the spreadsheet requires. When a new image is stored in the cache it can look at the amount of memory left and perhaps throw out another image. Because it holds all the images it can consider the entire situation, locating the most suitable picture to dispose of.
If the value received by a cell is an image then the cache notes this fact and stores the image. Later if the cells value is needed then the cell will ask the image cache for its value. It may or may not be present depending on the image size requested and the memory resources available. If the image is present then it may be returned to the cell immediately for use. If not then the cache will force the cell to reevaluate its program . This will generate the required image to be stored in the cache and used by the cell. The problem of selecting which image to dispose is much like that of virtual memory page replacement, a similar set of algorithms could be used to reduce cache misses. If a cells program changes then all of the cell's images can be removed from the cache.
An additional requirement for the cache is the ability to cancel the requests for an image. This can happen if the user is changing the spreadsheet quickly without waiting for results to be fully calculated.
The implementation of the cache in the large image spreadsheet uses an auxiliary object, the Image Holder, to handle all the images for an individual cell. When a request for an image is received from a cell the appropriate holder is found and the checked for that image size. When ever a cell tries to store an image the holder is checked and if absent, the image is added. The current image cache does not monitor memory usage or remove images unless told to by the cell.
The Interpreter Object
The interpreter we designed was intended to provide a flexible, and powerful way of calulating the values of cells. It was designed to allow the spreadsheet to handle expressions of different types, and to allow the user to include cell references in the cell expressions, thus enabling powerful chains of operations to be constructed.
The interpreter was designed to evaluate expressions of text, number and image data, and return the values to the cell that requested the information. Any cell references included in the expressions would be evaluated, possibly involving the calculation of further expressions before the parent request could be calculated. The numeric expressions allowed by the interpreter are the same as the expressions in any traditional spreadsheet, typically involving addition, subtraction, multiplication and division.
The text expressions are simply a text string entered by the user. The image expressions involve operations on image data using the HIPS package of functions (see appendix E for further details), including LOAD, ROTATE, INVERT and TRANSLATE.
The interpreter system operates by maintaining a queue of requests, ordered on priority.These requests can be cancelled at any time. The requests are taken from the queue, highest priority first, and the program object is extracted from the request. The AST of the program object is then evaluated, and the value obtained is returned to the calling cell. If any cell references are encountered in the expression, then the evaluation of the parent expression is suspended until a value is returned by the cell referenced. This may involve the referenced cell sending a child request to evaluate the data needed by the parent request before the data needed can be returned to the parent request. The interpreter will also check the data types of any values returned by the cells, and if the data type of a value returned does not match the type expected by the parent request, then the request will return an error value to the cell requesting the data. This design was the original aim for the interpreter, and we have managed to evaluate all the types of expressions correctly, and return the values to the cells, but the cell references feature has not been implemented because of time constraints, and compiler errors.
External Model
Implementing the interface to drive the spreadsheets internal model was done using the Tcl/Tk environment. Tcl is a scripting language easily extended with new commands, the Tk extension allows graphical user interfaces to be defined in Tcl. This environment has the advantage of separating the interface module from the main application, with this organisation it is easy to extend and experiment with different interface designs.
There were four main problems to solve in supplying the spreadsheet interface, these were: to create a new Tcl command for driving the spreadsheet, to create a Tk graphical user interface to drive the command, to establish a method for spreadsheet changes and outputs to be sent to the graphical user interface and to extend Tk with support for displaying HIPS format images held in memory.
The Spreadsheet Command
The Tcl commands would be implemented in C code as part of an extended interpreter. Design of these spreadsheet commands was based on a simple example for generating counter objects. Each call to the "spreadsheet" command creates a new spreadsheet object of specified dimension. For each object a new command is added to the interpreter during run time with an associated name. This new command is used for driving the spreadsheet by allowing: formulae to be inserted and retrieved from cells, processing time to be explicitly allocated to the internal model and for cell data values to be requested.
Feedback times would need to be as fast as possible for each operation, a single "putformula" could result in many cell images needing recalculated. It was for this reason that the "doidletasks" operation was created, rather than having to wait for a "putformula" to finish all calculations. We wanted the flexibility to decide when was most appropriate to do time consuming work, generally this would be done during idle user time.
A typical shell session using these commands would be as follows:
% spreadsheet 30 30 spread0 % set f =LOAD(mandrill.rgb) =LOAD(mandrill.rgb) % spread0 putformula A1 f Put the formula! % spread0 getformula A1 f Got the formula! % puts $f =LOAD(mandrill.rgb) % spread0 doidletasks % spread0 getdata A1 512 512
The Interface defined in Tk
The graphical user interface defined using Tk would need to provide some essential features for interacting with the spreadsheet. Of paramount importance were display of cell values, selection of cells and entering of cell formulae. These were provided in the familiar way with an entry widget in the top part of the display and the grid of cells taking up the main part, each cell would position its value in the centre of the cells widget. The selected cell was made identifiable by indenting the widget and changing its background colour to a darker shade of grey, a label next to the formula line entry was also added for quick reference.
Other features included resizing buttons for the spreadsheet grid. These would also have the effect of requesting cell values be recalculated since images might not fit in the new sized cells. Floating windows displaying large version of images were also supported, the display option of full colour or grey scale display was also given both for images on the grid and in windows. Some minor additions were placed in the menu entries allowing a short cut for image loading and a copying and pasting function for cell formulae.
The interface was also responsible for requesting calls to perform calculations. This would ideally have been done during any available idle user time, however some problems with the idle event handling in Tk meant that instead an alternative method had to be used where calls were made on regular time intervals.
Communicating Changes to the Interface
The only method available for communicating changes in the spreadsheet to the graphical interface was to use the Tcl C library procedures to changes variable in the script and to generate strings for Tcl to execute. This simple method allowed great flexibility but did however mean having to rely on certain variable names.
Implementations were needed for a number of procedures which the spreadsheets internal model would call. These would deal with cases where a cell has been changed requiring its value to be recalculated and when the spreadsheet had produced a new data value ready for display, different procedures were written for the display of all types of value.
For an image that had been created there was the added problem of deciding whether it was intended for display in the cell or in the associated viewing window. A crude but effective answer to this problem was to compare the images size with that expected for window images, images meant for the window would be at least half as large as this size.
HIPS Image Support
Image support in Tk is supplied by a set of image commands, these allow image creation from a small selection of popular file types, of which HIPS images are not included. Support is also provided for creating an images from a string however most image types only allow reading from file. Once an image is created Tk is able to display it in as necessary controlling aspects such as clipping and colour dithering. Images can be shown in most widgets type and it is by this method that the images of our spreadsheet were shown in the cells.
The problem still remained however to add support for HIPS format images, and in particular displaying those created by the spreadsheet in memory. The decision was made to support only RGB HIPS images since they would be the most commonly used. Extending the interpreter to allow these images to be loaded from disk was a simple task involving use of HIPS library functions. However since cell images would have to be read from memory this was not terribly useful to us. The only solution was to make clever use of Tk's string field for images. The normal use of the string field is to supplied data representing the image itself, this is then converted for Tk by providing a string reading procedure for that image type. Our approach, however, was to pass a pointer to the image using the string field, the procedure for reading the image would then having to do some awkward conversions before referencing the pointer to access the image data in memory. This approach, although clumsy, proved successful and our problem was solved.
| The Formula Language | Conclusion |
| About this site | Spreadsheet For Large Images | © Matthew Caryl |